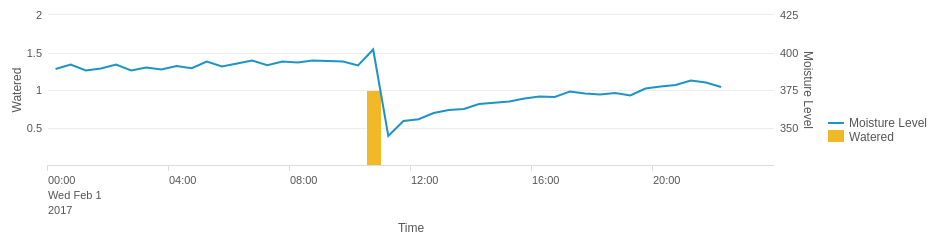
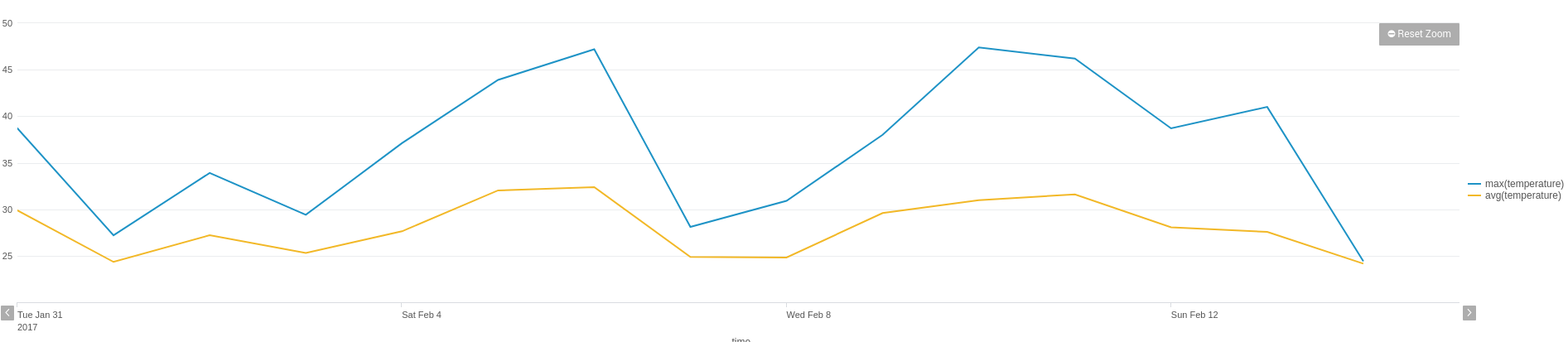
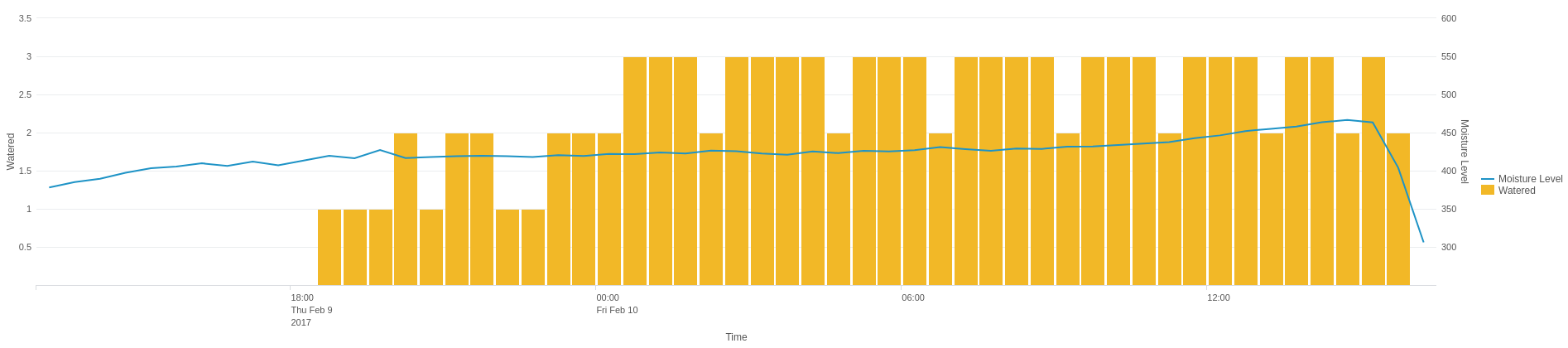
ServiceNow’s service portal offers a lot of flexibility for customers wanting to offer complex and sophisticated offerings to their users. Catalog client scripts can run on load, on change and on submit, but often there’s a need for a common library of functions to be shared by these scripts (so they’re maintained in just one place and produce consistent results).
For example, in this case, if the start date, end date or the SAP position changes, the same script needs to run to calculate who the approvers are for a particular request.
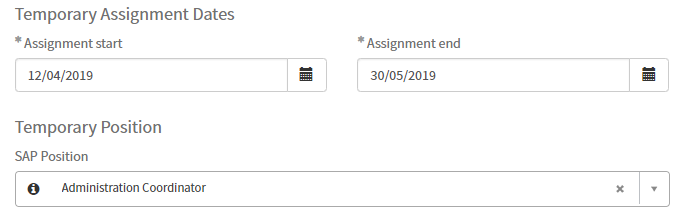
Rather than having three separate versions of the same script, we want to be able to store our logic in one place. Here’s how we can do it.
Isolate Script
Although the latest versions of ServiceNow (London, Madrid, etc) allow for scripts to be isolated or not, giving ServiceNow admins either the option of protecting (isolating) their scripts or accessing broader libraries, in practice, this can be a little frustrating to implement, so in our example, we’ll use an alternative method to introduce external javascript libraries.
UI Scripts
UI scripts, like the one listed below, are very powerful, but they’re also very broad, being applied EVERYWHERE and ALWAYS, so we’ll tread lightly and simply add a function that sets up the DOM for access from our client scripts.
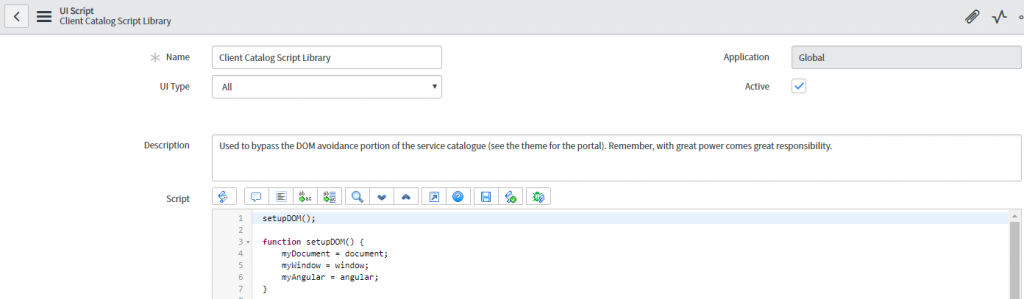
As you can see, we now have some variables we can reference to give us access to the document object, the window object and the angular object from anywhere within ServiceNow.
In theory, we could attach our SAP position changes script here and it would be accessible but it would also be loaded on EVERY page ServiceNow ever loads, which is not good. What we want is a global function accessible only from WITHIN our catalog item, so we’ll put this in an ON LOAD script using our new myWindow object.
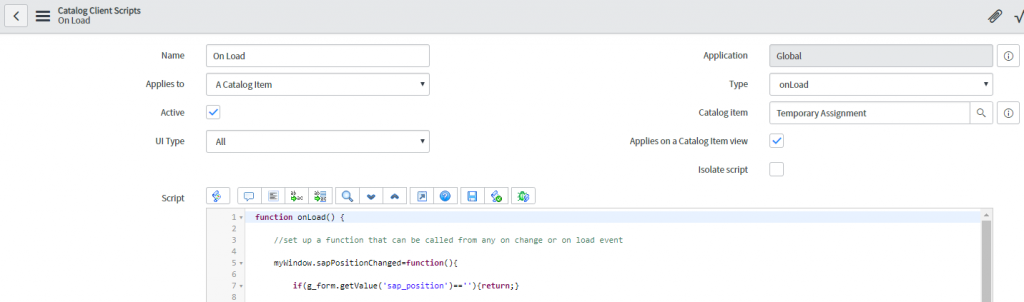
The format we’re using is…
myWindow.functionName = function(){
console.log('this is an example')
};
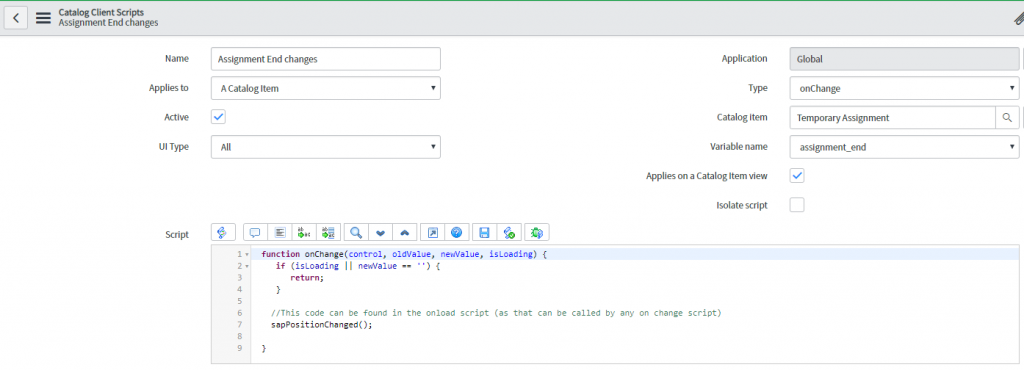
This function can then be called from ANYWHERE within our catalog item (on change or on submit). Also, notice the semi-colon at the end of the window function. Don’t forget this as it is important as we’re altering an object.
Now, though, any time we want to call that common function, we can do so with a single line of code.
Following this approach makes maintenance of the logic used by the approval process easy to find and alter going forward.