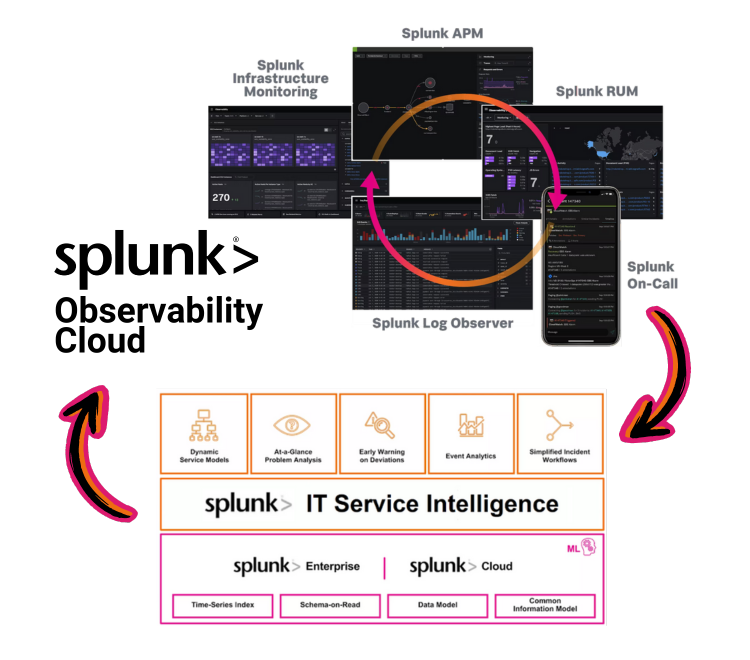
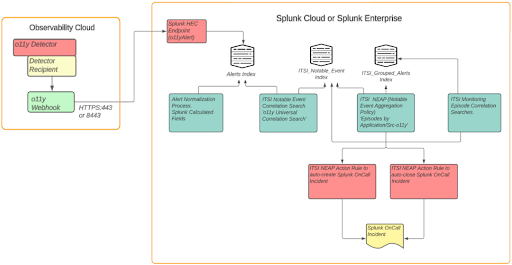
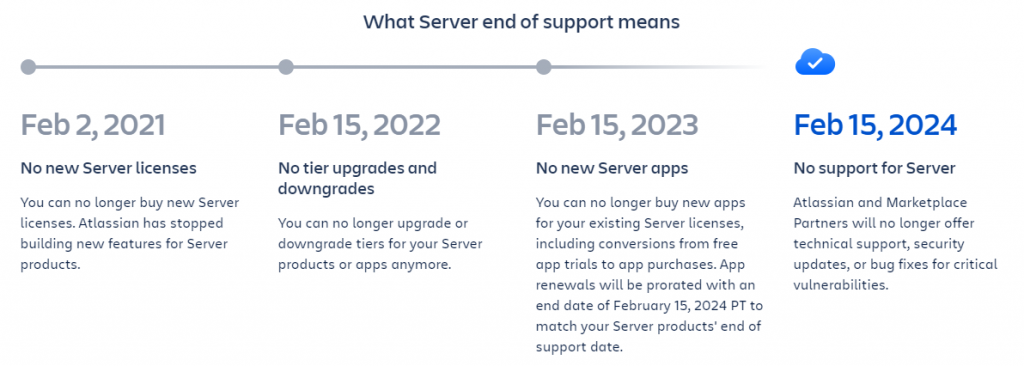
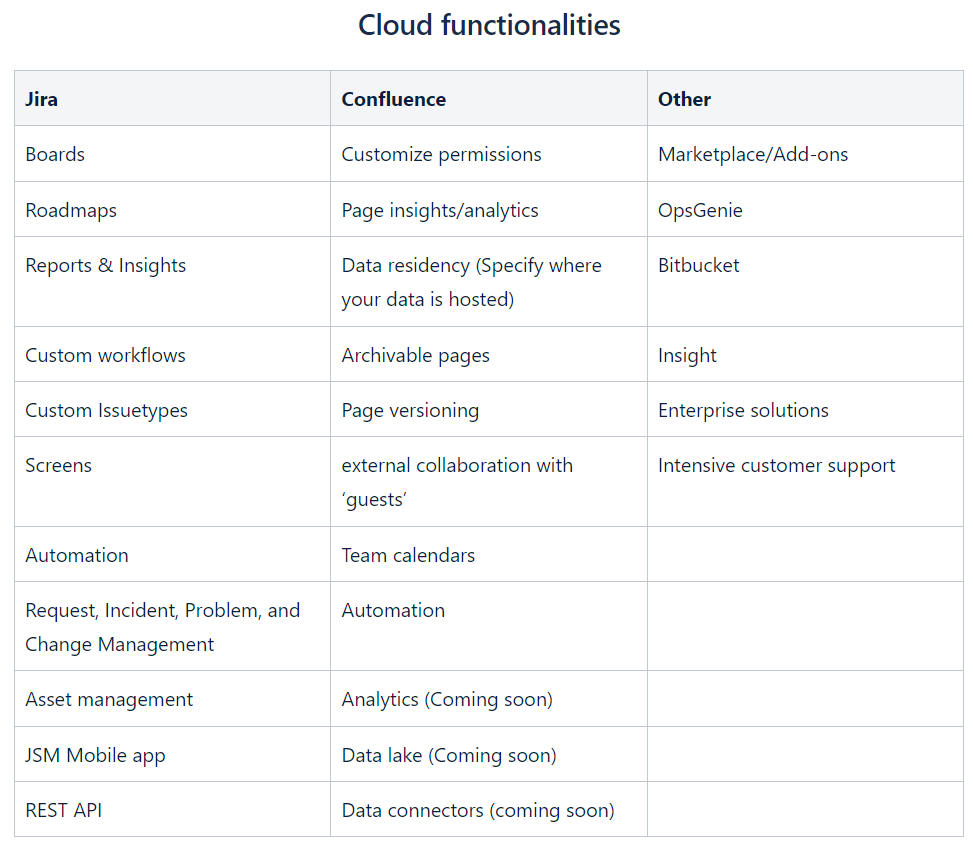
With more and more time spent online, our expectations for a slick and intuitive experience have increased. This has extended beyond our day-to-day personal activities, to include our online interactions in the workplace. By not providing user-friendly interfaces to their employees, organisations risk disengagement and diminished productivity levels.
What is UX?
When we talk about UX in the context of ServiceNow, we’re referring to how users perceive and interact with the platform. A good UX means that ServiceNow is not only functional, but also intuitive, efficient, and tailored to assist users in performing their tasks with minimal friction and maximum satisfaction.
Why UX Matters?
Potential outcomes of a overall negative user experience are:

The relationship between users and technology is tangible, and has a direct impact on their output and satisfaction when using a platform. For most users, this connection is solidified through their interactions with outward-facing interfaces such as a self-service portal or chatbot. For the full value of a platform like ServiceNow to be realised by an organisation, its employees must feel confident and empowered when navigating and using the platform.
Without this level of trust between user and technology, an organisation will find it more difficult to drive adoption of the platform and improve their ways of working. Frustrated users may be prone to reverting back to old ways of getting things done, like emailing someone directly. This can lead to the resurfacing of issues of traceability and accountability that ServiceNow was intended to solve.
Creating A Positive UX In ServiceNow
To keep up with user expectations, you need a platform that has its finger on the pulse of modern ways of working. The ServiceNow ecosystem is constantly evolving to meet the changing needs of a modern workplace, with updates providing new interfaces that are focussed on providing engaging experiences to drive productivity with employees and enhance user satisfaction. Updates have previously included:
- Self-Service with Service Portal
- Instant Assistance with Virtual Agent
- Mobile Accessibility with NOW Mobile
- Modern Design with UI Builder
- Personalised Experiences with Configurable Workspaces and Employee Center
- Real-time Collaboration with Sidebar
- Generative AI Assistance with NOW Assist

How To Keep Up
With trends and expectations evolving so rapidly, it can be hard for organisations to keep up. This can be especially true with regards to user interfaces and experiences, where the benefits may not be easily measurable.
JDS offers a comprehensive package to help organisations uplift their user experiences in ServiceNow to ensure they are getting the most out of the platform. This User Experience Review & Analysis evaluates an organisation’s readiness to improve their user experience in the ServiceNow platform by assessing the current state of the platform against three main principles:
- Available Products and Features
- Standards and Governance
- Technology and Security
The end result is a clear and actionable strategy to adapt and modernise interfaces through which users engage with the ServiceNow platform to improve the overall experience and increase productivity.
Part Two of this blog series will outline some actionable strategies to take the ServiceNow UX from OK to Outstanding…