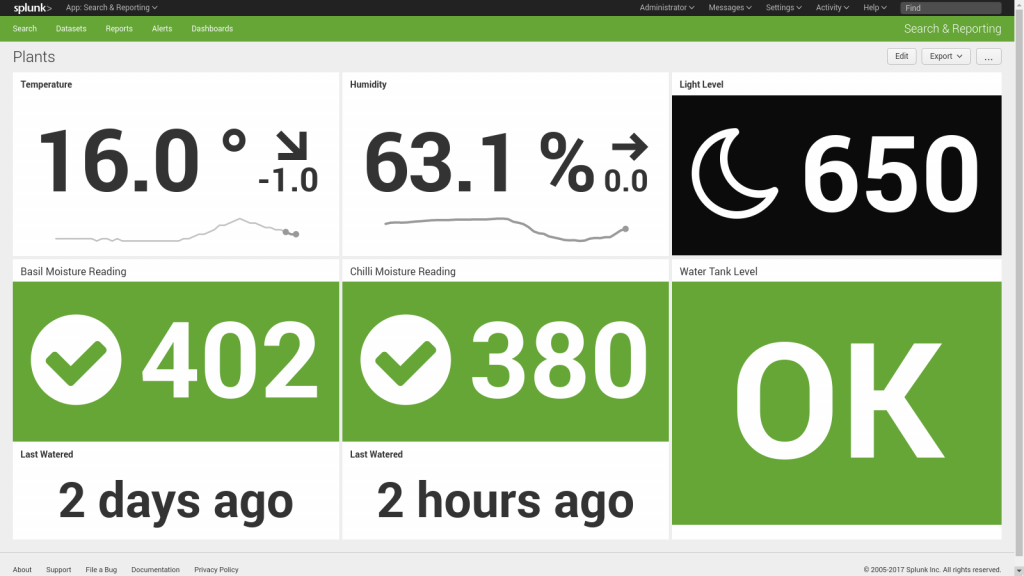
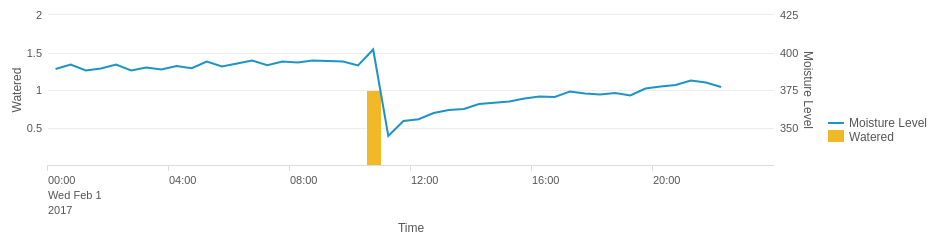
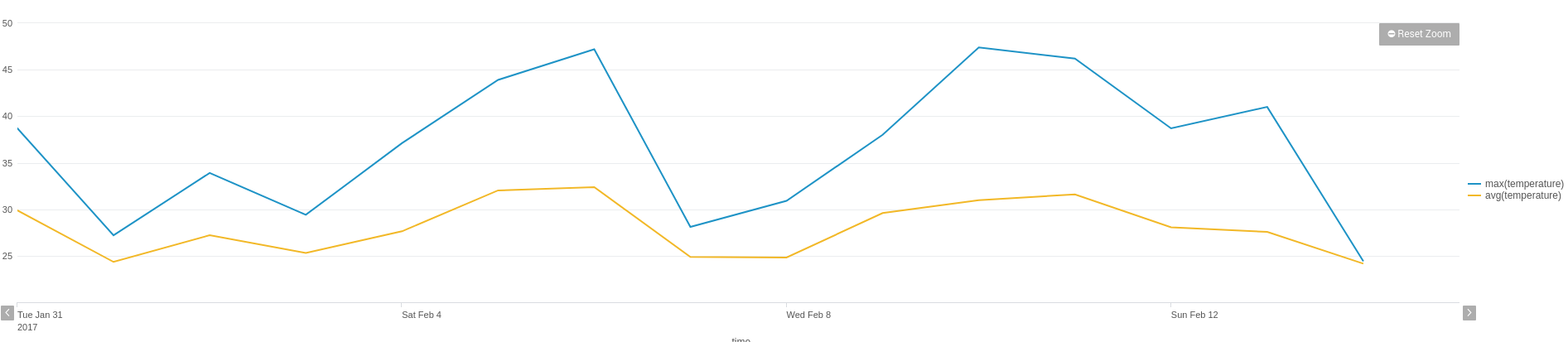
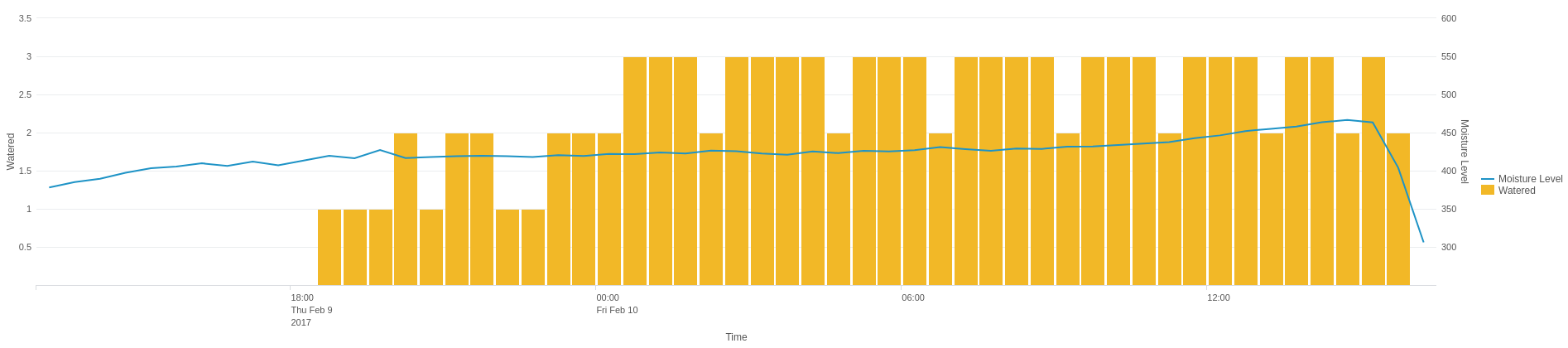
Understanding how your SAP system is performing can be a time-consuming process. With multiple environments, servers, APIs, interfaces and applications, there are numerous pieces to the puzzle, and stitching together the end-to-end story requires a lot of work.
That’s where SAP PowerConnect can assist. This SAP-certified tool simplifies the process by seamlessly collating your SAP metrics into a single command console: Splunk. PowerConnect compiles and stores data from each component across your SAP landscape and presents the information in familiar, easily accessible, and customisable Splunk dashboards. When coupled with Splunk’s ability to also gather machine data from non-SAP systems, this solution provides a powerful insight mechanism to understand your end user’s experience.
Given the magnitude of information PowerConnect can collate and analyse, you may think that setting it up would take days—if not weeks—of effort for your technical team. But one of PowerConnect’s key features is its incredibly fast time to value. Whatever the size of your environment, PowerConnect can be rapidly deployed and have searchable data available in less than ten minutes. Furthermore, it is highly customisable in providing the ability to collect data from custom SAP modules and display these in meaningful context sensitive dashboards, or integrate with Splunk IT Service Intelligence.
Here are some quick tips for customising your SAP data with PowerConnect.
1. Use the out-of-the-box dashboards
SAP software runs on top of the SAP NetWeaver platform, which forms the foundation for the majority of applications developed by SAP. The PowerConnect add-on is compatible with NetWeaver versions 7.0 through to 7.5 including S/4 HANA. It runs inside SAP and extracts machine data, security events, and logs from SAP—and ingests the information into Splunk in real time.
PowerConnect can access all data and objects exposed via the SAP NetWeaver layer, including:
- API
- Function Modules
- IDoc
- Report Writer Reports
- Change Documents
- CCMS
- Tables
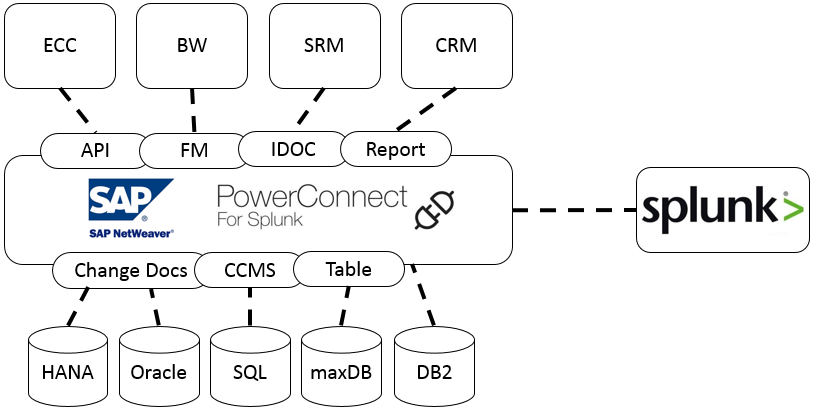
If your SAP system uses S/4 HANA, Fiori, ECC, BW components or all the above, you can gain insight into performance and configuration with PowerConnect.
To help organise and understand the collated data, PowerConnect comes with preconfigured SAP ABAP and Splunk dashboards out of the box based on best practices and customer experiences:
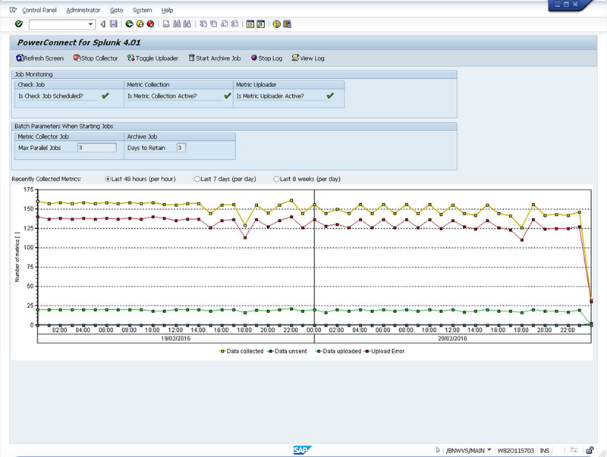
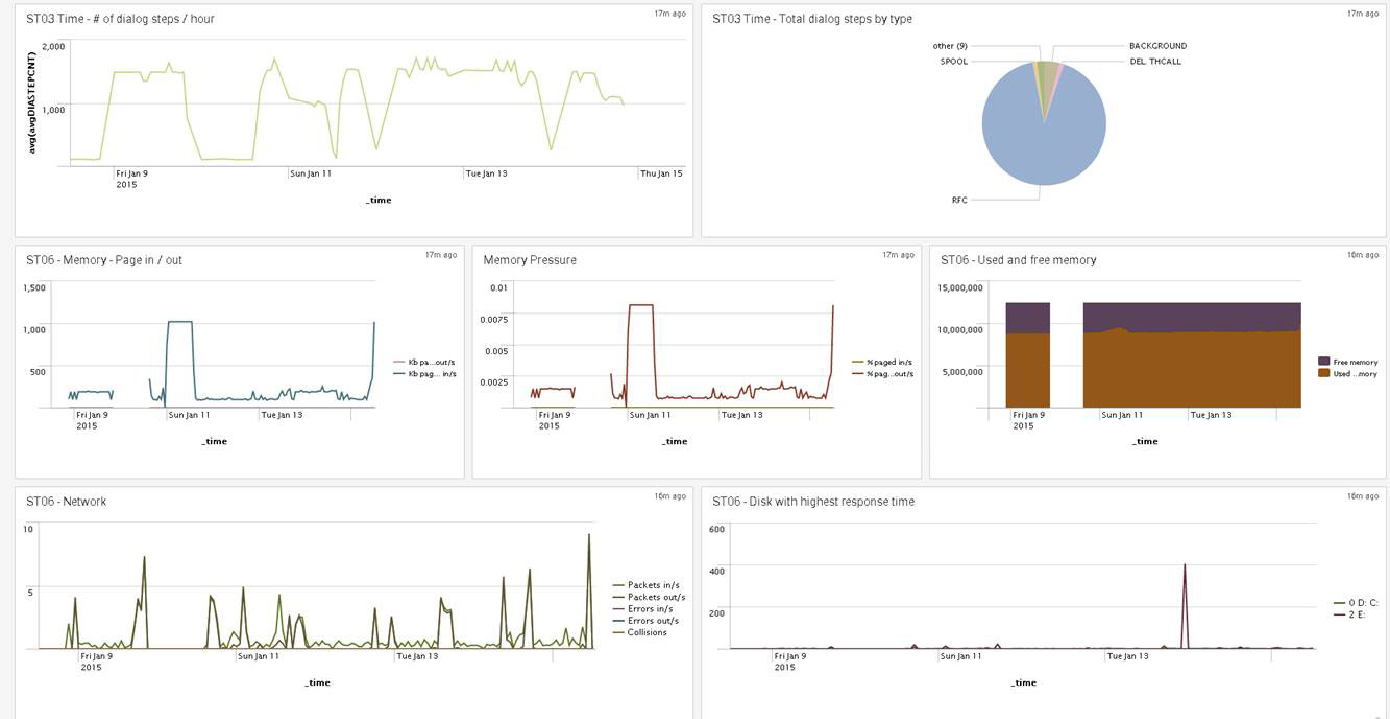
PowerConnect centralises all your operational data in one place, giving you a single view in real time that will help you make decisions, determine strategy, understand the end-user experience, spot trends, and report on SLAs. You can view global trends in your SAP system or drill down to concentrate on metrics from a specific server or user.
2. Set your data retention specifications
PowerConnect also gives you the ability to configure how, and how long, you store and visualise data. Using Splunk, you can generate reports from across your entire SAP landscape or focus on specific segment(s). You may have long data retention requirements or be more interested in day-to-day performance—either way, PowerConnect can take care of the unique reporting needs for your business when it comes to SAP data.
You have complete control over your data, allowing you to manage data coverage, retention, and access:
- All data sets that are collected by PowerConnect can be turned off, so you only need to ingest data that interests you.
- Fine grain control over ingested data is possible by disabling individual fields inside any data sets.
- You can customise the collection interval for each data set to help manage the flow of data across your network.
- Data sets can be directed to different indexes, allowing you to manage different data retention and archiving rates for different use cases.
3. Make dashboards for the data that matters to you
You have the full power of Splunk at your disposal to customise the default dashboards, or you can use them as a base to create your own. This means you can use custom visualisations, or pick from those available on Splunkbase to interpret and display the data you’re interested in.
Even better, you’re not limited to SAP data in your searches and on your dashboards; Splunk data from outside your SAP system can be correlated and referenced with your SAP data. For example, you may want to view firewall or load balancer metrics against user volumes, or track sales data with BW usage.
4. Compare your SAP data with other organisational data
It is also possible to ingest PowerConnect data with another Splunk app, such as IT Service Intelligence (ITSI) to create, configure, and measure Service Levels and Key Performance Indicators. SAP system metrics can feed into a centralised view of the health and key performance indicators of your IT services. ITSI can then help proactively identify issues and prioritise resolution of those affecting business-critical services. This out-of-the-box monitoring will give you a comprehensive view of how your SAP system is working.
The PowerConnect framework is extensible and can be adapted to collect metrics from custom developed function modules. Sample custom extractor code templates are provided to allow your developers to quickly extend the framework to capture your custom-developed modules. These are the modules you develop to address specific business needs that SAP doesn’t address natively. As with all custom code, the level of testing will vary, and gaining access to key metrics within these modules can help both analyse usage as well as expose any issues within the code.
5. Learn more at our PowerConnect event
If you are interested in taking advantage of PowerConnect for Splunk to understand how your SAP system is performing, come along to our PowerConnect information night in Sydney or Melbourne in May. Register below to ensure your place.